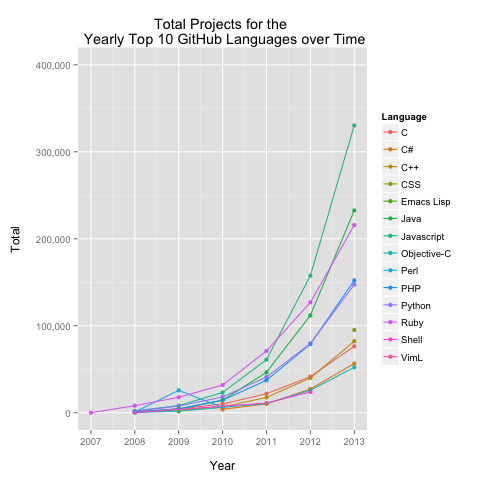
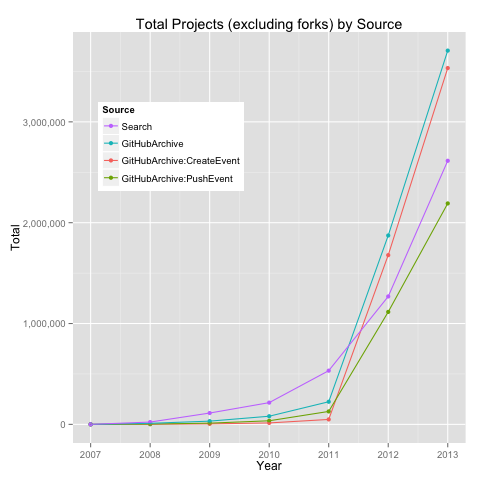
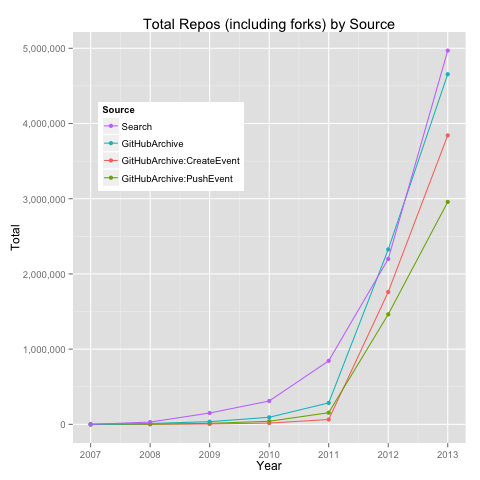
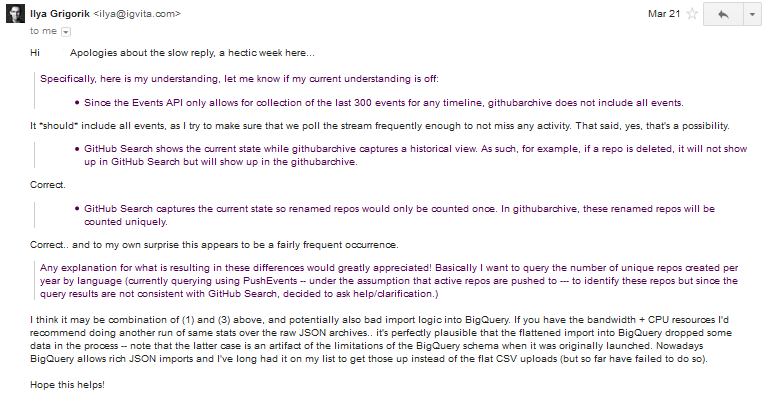
I first learned about DataMonkey about a month ago on DataTau.
As a voracious consumer of MOOCs and a lover of all things data, I was curious about this new CodeAcademy-esque learning tool on databases (and, honestly, the monkey theme was too catchy to ignore). Offering two tracks in 1) Spreadsheets and 2) SQL, DataMonkey looked like a fun way to pick up the basics of creating spreadsheets, manipulating data, and querying databases. But, if you are already an Excel wizard or SQL programmer, learning how to input formulas in spreadsheets and write SELECT statements isn’t quite anything new. While not a expert in either, I’ve clocked enough hours munging data in Stata and R that these are far from foreign concepts. Trying out DataMonkey was thus less to learn spreadsheet formulas and SQL queries but to check out how – if at all – this new learning tool may add that extra “je ne sais quoi” to the many, many already out there.


Spreadsheets
- Learning the Spreadsheet Basic
- Formulas and Conditions
- Basic Text Formulas
- Nest Formulas
I did not complete all four lessons in the track, though not out of waning motivation. I was only minutes into the track, starting Lesson #2: Formulas and Conditions, and was excited to rack up my DataMonkey points when I hit up against a snag. An #ERROR! falsely flagging that an inputted formula was incorrect blocked me from moving forward. I double-checked that my eyes weren’t somehow playing games and replicated the formula successfully in Excel. What is going on? Seems like a bug.

True enough, after contacting the co-founders, I got a response: “Your formula doesn’t work because of error in the program code. Now we fix it and you can continue education.
Thanks a lot for your help and callback.” I checked back on the lesson ~8 hours later and the bug wasn’t fixed yet. I decided to skip the rest of the Spreadsheet track and jump to the SQL track. I wasn’t picking up anything new and had the gist of DataMonkey’s approach. Nothing exciting.
SQL
- Lesson 1
- Guess SQL. Beginners level.
- Guess SQL. Basic level.
- Guess SQL. Test I.
- Guess SQL. Level 3.
- Guess SQL. Level 4.
- Lesson 2
- Preamble. Or what to do when you see SQL console.
- Story I. Part I. About select, where and their logical friends who help our buddy Buggy.
- Story I. Part II. About select, where and their logical friends who help our buddy Buggy.
- Story II. Part I. About group by, having and how math functions can help in punishing bad guys.
- Story II. Part II. About group by, having ad how math functions can help in punishing bad guys.
- Case I. Online shop.
Lesson 1

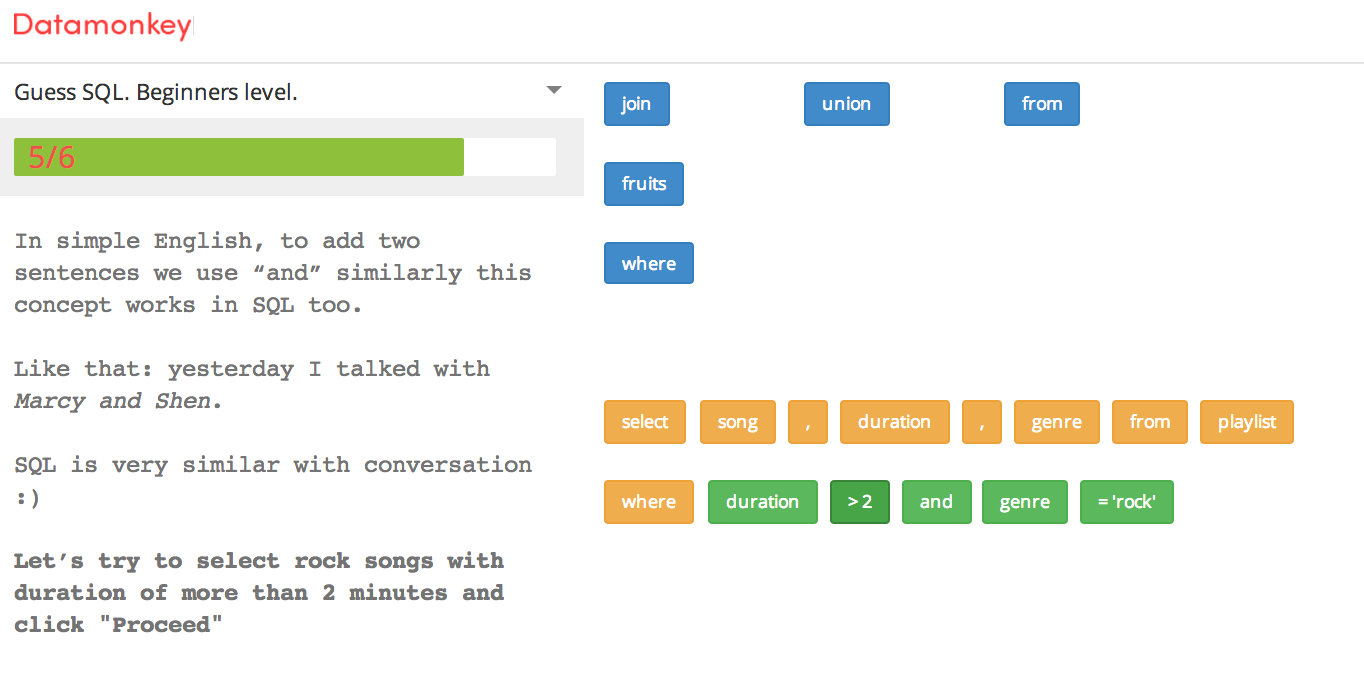
Lesson 1 is MadLib-style: you select words to fill in the blanks in a SQL statement. Of course, unlike MadLibs, each word must be in its correct spot to make sense. Unfortunately, you can blindly click, click, click in the word bank and the words will fill into their appropriate spots automatically.
I am not the fan of this approach. Sure, it may be a less intimidating than writing SQL statements from scratch but it doesn’t quite lay the groundwork of how to build out a complete SQL statement from an blank slate, starting with a question like “What are top 10 MOOCs by number of active users?”. I’ve seen this approach before in kids’ math workbooks e.g., fill in the blank with the correct operator: 5 __ 2 = 3. I’m not an expert in teaching methods so I am not aware of the potential merits to this fill-in-the-blank approach but I prefer the approach of learning while doing — and specifically, doing it how you will do it in “real-life”.
Well, sure enough, Lesson 2 addresses this concern.
Lesson 2
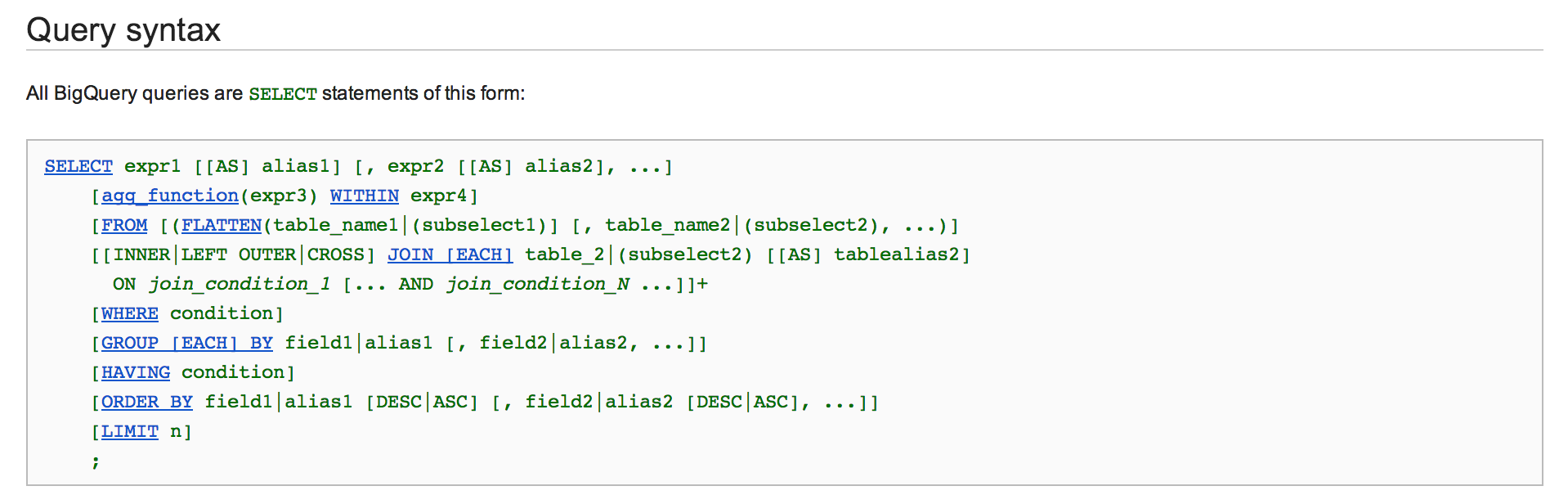
Lesson 2 uses the console where you are prompted to write SQL statements . The approach is CodeAcademy-esque though DataMonkey is more barebones in its features and functionalities e.g., hints, Q&A forum.
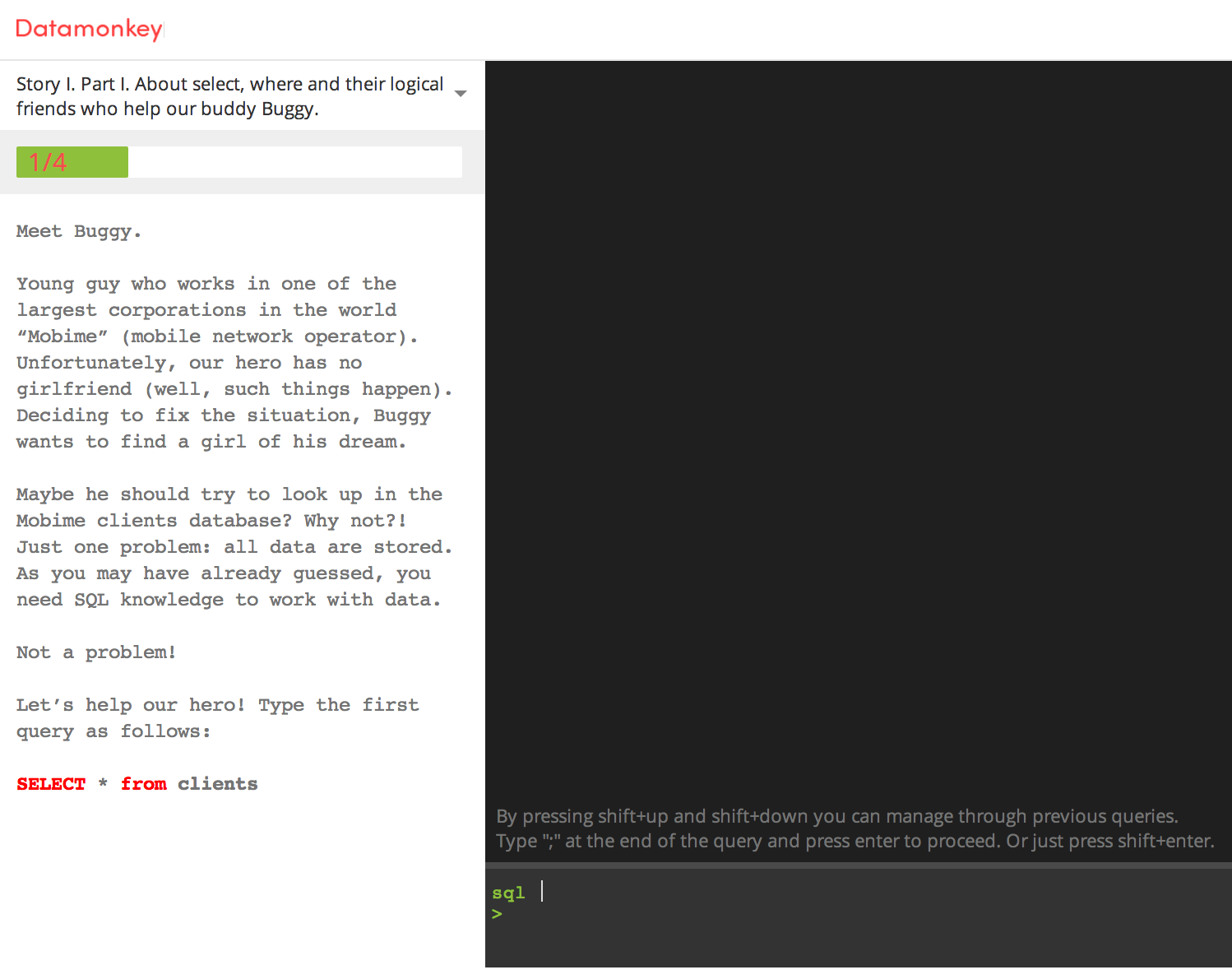
Also, DataMonkey more often than not simply gives you the SQL statement to type in. The exercise then simply becomes a mindless act of copying rather than an active process of figuring out how to query from plain English to SQL.



Another thing you may notice from the example SQL statements above is the inconsistency of how the tables are called: clients, CLIENTS, Clients. For especially newbies, this would be incredibly confusing. Are table names not case-sensitive? How about variable names?
Similarly, looking at queries of specific values, the question may arise: are variable values not case-sensitive?
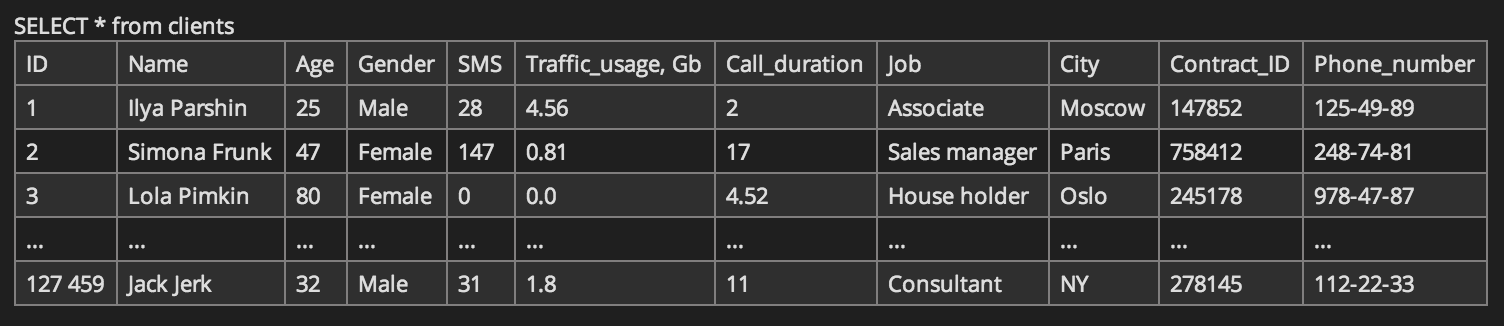

I had to Google to figure out exactly what was going on. I knew that SQL keywords such as SELECT, FROM, WHERE were case-insensitive but I wasn’t certain about table names, column names, and variable values. Coming from Stata, where these are all case-sensitive, I had assumed that Gender = ‘female’ is not equal to Gender = ‘Female’ is not equal to gender = ‘FEMALE’ and so on. Well, I learned something new:
SQL case sensitive string compare
Case sensitivity in SQL statements
I still have some homework to do on how case sensitivity differs by DBMS e.g., Oracle, MySQL, PostgreSQL, SQL Server, etc and operating system e.g., Windows vs. Unix/Linux. But all this considered, even if we don’t have to worry about case-sensitivity within DataMonkey’s environment, I would have appreciated consistency or, if not, an explanation of the why this works:
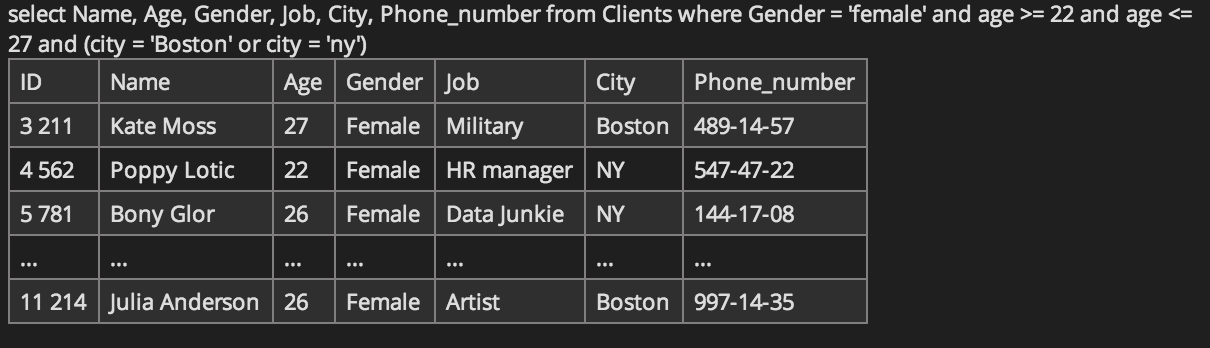
Wish List
I’ll definitely keep an eye out as DataMonkey develops its content and polishes its learning tool. My wish list for DataMonkey includes:
- ability to save my latest state i.e., where I was last in the sequence of lessons
- ability to move between sections within a lesson
- consistency in code examples
- detailed error messages to help debug
- more advanced levels (currently levels range from [beginners of beginners, medium complexity])
- new lessons in R and Python